Semantic Search Development with C# using Ollama & VectorDB orchestrate in .NET Aspire
We’re going to create Search Page for Semantic Search with Using Ollama and VectorDB in a .NET application. We’ll integrate AI with .NET Aspire to orchestrate AI services efficiently and use Microsoft.Extensions.AI to build unified AI workflows.

By the end of this article, you’ll have a clearer understanding of how to set up a semantic search pipeline, generate embeddings, store them in a vector database, and query them efficiently from your .NET application.
What is Semantic Search?
Semantic search focuses on the meaning or context behind words rather than simple string matching. Instead of comparing raw text, we compare high-dimensional vector representations of words, sentences, or documents, known as embeddings.
- Embeddings transform textual data into numerical vectors.
- These vectors preserve semantic information: two pieces of text with similar meaning end up as vectors close together in the vector space.

The general process:
- Text to Embeddings: Convert text into vectors using an embedding model.
- Storage: Store these vectors in a database designed for efficient vector similarity lookups.
- Query: Convert user queries to vectors, then perform a similarity search to find the most semantically relevant results.
Why Ollama for LLM Capabilities?
Ollama is an open-source toolkit that helps you run large language models (LLMs) locally. While many embedding services exist online, Ollama stands out for its ability to:
- Run locally without requiring cloud APIs.
- Provide large model capabilities for generating embeddings or performing natural language tasks.
- Offer easy integration points with your .NET applications.
In a typical setup, you can deploy Ollama as a local or containerized service that your .NET application communicates with. Ollama can generate embeddings (vector representations) for each piece of text you want to index.
Why a Vector Database?
A Vector Database (or VectorDB) is specifically built to index and query vectors. Traditional relational databases or document databases do not excel at high-dimensional approximate nearest-neighbor (ANN) searches.
Key benefits of using a dedicated VectorDB:
- Fast Similarity Search: Provides specialized indexes (e.g., HNSW, IVF) for high-dimensional vector queries.
- Scalability: Handles large datasets of embeddings.
- Metadata Integration: Often includes features to store metadata or references alongside vectors (think text or document links).
Popular VectorDB options include Pinecone, Weaviate, Qdrant, or even specialized modules like Redis Stack (Redis for vector similarity).
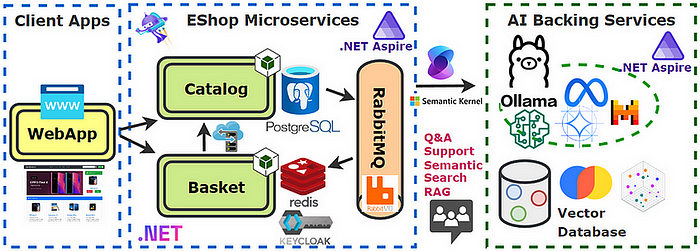
Architectural Overview in .NET Aspire
Below is a high-level overview of how everything ties together in a .NET Aspire (or ASP.NET Core) application:

Embeddings Service (Ollama)
- A containerized microservice that receives text and returns embeddings.
- Hosting: we add a model (all-minilm) in Ollama for generating embeddings.
VectorDB
- A dedicated service to store and retrieve embeddings.
- We store & retrieve these embeddings using a collection from Microsoft.Extensions.VectorData.Abstractions or a real vector database.
.NET Aspire Distributed App
- Indexing Flow: Takes in raw documents, calls Ollama to get embeddings, stores embeddings + metadata in VectorDB.
- Query Flow: Takes in user query, calls Ollama to get embedding, queries VectorDB for nearest neighbors, and returns top results.
Hosting Integration for Ollama all-minilm Embeddings Model
we’ll add the all-minilm embeddings model to our Ollama instance, enabling advanced semantic or vector-based queries in your .NET Aspire solution.
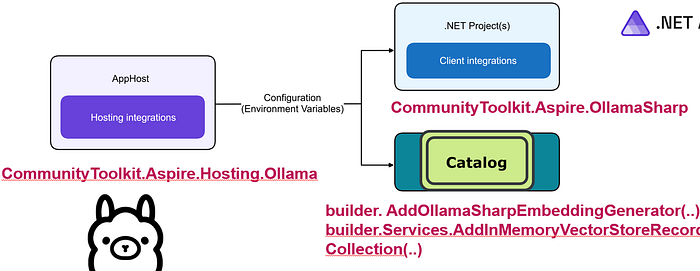
AppHost
Install Package
CommunityToolkit.Aspire.Hosting.OllamaThis library powers the Ollama hosting integration, letting you specify which models you want (like llama3.2, all-minilm, or others) for chat or embeddings.
AppHost Program.cs Code Snippet
var builder = DistributedApplication.CreateBuilder(args);
// Backing Services
var ollama = builder
.AddOllama("ollama", 11434)
.WithDataVolume()
.WithLifetime(ContainerLifetime.Persistent)
.WithOpenWebUI();
var llama = ollama.AddModel("llama3.2");
var embedding = ollama.AddModel("all-minilm");
// Projects
var catalog = builder
.AddProject<Projects.Catalog>("catalog")
.WithReference(catalogDb)
.WaitFor(catalogDb)
.WithReference(rabbitmq)
.WaitFor(rabbitmq)
.WithReference(llama)
.WaitFor(llama)
.WithReference(embedding)
.WaitFor(embedding);
...- .AddOllama(“ollama”, 11434): Creates an Ollama resource, naming it “ollama” and fixing port 11434.
- .AddModel(“llama3.2”) might be your main chat model;
- .AddModel(“all-minilm”) is specifically for embeddings.
We also reference llama if you need a chat-based model. This injects environment variables like ConnectionStrings__ollama-all-minilm
This ensures the embedding resource is fully up before the Catalog microservice starts, and it also injects the model info (like Endpoint=http://localhost:11434;Model=all-minilm) into Catalog.
Client Integration Packages with SemanticKernel and Microsoft.Extensions.VectorData
We’ll examine Microsoft.Extensions.VectorData libraries and how they collaborate with SemanticKernel to provide in-memory or persistent vector stores for your .NET microservices (like the Catalog service).

What is Microsoft.Extensions.VectorData ?
Microsoft.Extensions.VectorData is essentially an abstraction or interface layer, letting you manipulate vector data without coding directly against a specific database or store.
Think of it like Entity Framework for embeddings — create, read, update, delete on vector-based records in a consistent manner, no matter the underlying vector DB or service.
How to get started ?
The easiest way to get started with Microsoft.Extensions.VectorData abstractions is by using any of the Semantic Kernel vector store connectors. We’ll be using the in-memory vector store implementation.
Install Packages
Microsoft.SemanticKernel.Connectors.InMemory
Microsoft.Extensions.VectorData.Abstractions- Microsoft.Extensions.VectorData.Abstractions for the vector store interfaces.
- Microsoft.SemanticKernel.Connectors.InMemory for the in-memory record collection, allowing you to store embeddings in local memory.
Workflow Overview

- Generate embeddings using the model (like all-minilm from Ollama).
- Store them in your in-memory vector record collection.
- When a user queries, turn the query text into an embedding and run a cosine similarity or other measure to find best matches.
- Return relevant products or data.
Develop ProductVector Domain Entity for Storing Vector Data
We’ll create a ProductVector class in our Catalog microservice. The goal is to store embedding data for each product, enabling advanced semantic or vector-based search.
ProductVector.cs
using Microsoft.Extensions.VectorData;
using System.ComponentModel.DataAnnotations.Schema;
namespace Catalog.Models;
public class ProductVector
{
[VectorStoreRecordKey]
public int Id { get; set; }
[VectorStoreRecordData]
public string Name { get; set; } = default!;
[VectorStoreRecordData]
public string Description { get; set; } = default!;
[VectorStoreRecordData]
public decimal Price { get; set; }
[VectorStoreRecordData]
public string ImageUrl { get; set; } = default!;
[NotMapped]
[VectorStoreRecordVector(384, DistanceFunction.CosineSimilarity)]
public ReadOnlyMemory<float> Vector { get; set; }
}- [VectorStoreRecordKey] indicates the primary key for vector records.
- [VectorStoreRecordData] marks properties for storage in the vector record but not vector field.
- [VectorStoreRecordVector(384, DistanceFunction.CosineSimilarity)] signals this property holds the actual embedding array (size 384, using cosine similarity).
Register EmbeddingGenerator and VectorStore services in Catalog/Program.cs
We’ll see how to register the Ollama chat client, embedding generator, and an in-memory vector store in the Catalog microservice’s Program.cs.
using Microsoft.SemanticKernel;
var builder = WebApplication.CreateBuilder(args);
// Add services to the container.
builder.AddNpgsqlDbContext<ProductDbContext>("catalogdb");
builder.Services.AddScoped<ProductService>();
builder.Services.AddMassTransitWithAssemblies(Assembly.GetExecutingAssembly());
// Register Ollama-based chat & embedding
builder.AddOllamaSharpChatClient("ollama-llama3–2");
builder.AddOllamaSharpEmbeddingGenerator("ollama-all-minilm");
// Register an in-memory vector store
builder.Services.AddInMemoryVectorStoreRecordCollection<int, ProductVector>("products");
builder.Services.AddScoped<ProductAISearchService>();
builder.AddServiceDefaults();
var app = builder.Build();
..- builder.AddOllamaSharpChatClient(“ollama-llama3–2”) sets up a chat client for the llama model.
- builder.AddOllamaSharpEmbeddingGenerator(“ollama-all-minilm”) sets up embedding generation for all-minilm.
- builder.Services.AddInMemoryVectorStoreRecordCollection<int, ProductVector>(“products”) creates an in-memory collection named “products” for storing vector data (like ProductVector).
Explanation — 4 Core AI Configs
- OllamaSharpChatClient: IChatClient for user Q&A or conversation
- OllamaSharpEmbeddingGenerator: IEmbeddingGenerator for vector embeddings
- InMemoryVectorStore: A place to store embeddings (ProductVector objects)
- ProductAIService: The business logic that ties it all together
Develop ProductAIService.cs for Semantic Search Implementation
By injecting IChatClient for potential chat features, IEmbeddingGenerator for embedding generation, and a vector store collection for retrieval, we can deliver AI-driven results far beyond simple string matching.
ProductAIService.cs
using Microsoft.EntityFrameworkCore;
using Microsoft.Extensions.AI;
using Microsoft.Extensions.VectorData;
namespace Catalog.Services;
public class ProductAIService(
ProductDbContext dbContext,
IChatClient chatClient,
IEmbeddingGenerator<string, Embedding<float>> embeddingGenerator,
IVectorStoreRecordCollection<int, ProductVector> productVectorCollection)
{
private async Task InitEmbeddingsAsync()
{
await productVectorCollection.CreateCollectionIfNotExistsAsync();
var products = await dbContext.Products.ToListAsync();
foreach (var product in products)
{
var productInfo = $"[{product.Name}] is a product that costs [{product.Price}] and is described as [{product.Description}]";
var productVector = new ProductVector
{
Id = product.Id,
Name = product.Name,
Description = product.Description,
Price = product.Price,
ImageUrl = product.ImageUrl,
Vector = await embeddingGenerator.GenerateEmbeddingVectorAsync(productInfo)
};
await productVectorCollection.UpsertAsync(productVector);
}
}
public async Task<IEnumerable<Product>> SearchProductsAsync(string query)
{
if(!await productVectorCollection.CollectionExistsAsync())
{
await InitEmbeddingsAsync();
}
var queryEmbedding = await embeddingGenerator.GenerateEmbeddingVectorAsync(query);
var vectorSearchOptions = new VectorSearchOptions
{
Top = 1,
VectorPropertyName = "Vector"
};
var results =
await productVectorCollection.VectorizedSearchAsync(queryEmbedding, vectorSearchOptions);
List<Product> products = [];
await foreach (var resultItem in results.Results)
{
products.Add(new Product
{
Id = resultItem.Record.Id,
Name = resultItem.Record.Name,
Description = resultItem.Record.Description,
Price = resultItem.Record.Price,
ImageUrl = resultItem.Record.ImageUrl
});
}
return products;
}
}- InitEmbeddingsAsync() reads products from EF Core, calls the embeddingGenerator to produce a float vector, and upserts them into the vector store (productVectorCollection).
- SearchProductsAsync(query) checks if the embeddings exist — if not, it initializes them. Then it converts the query to an embedding and calls VectorizedSearchAsync with a top parameter (like 1 or 5).
- We map back to the original Product object for the final result.
Develop Search Endpoints in ProductEndpoints.cs for Semantic Search
We’ll expand our Catalog microservice’s ProductEndpoints.
ProductEndpoints.cs
group.MapGet(“aisearch/{query}”, async (string query, ProductAIService service) =>
{
var products = await service.SearchProductsAsync(query);
return Results.Ok(products);
})
.WithName("AISearchProducts")
.Produces<List<Product>>(StatusCodes.Status200OK);- aisearch/{query} calls the semantic method from ProductAISearchService.
Blazor FrontEnd Search Page Development
We’ll create a Search page in the WebApp that calls the Catalog microservice for either keyword or semantic search.
By toggling a checkbox, the user decides whether to run a standard substring query or use AI embeddings for more relevant results.
CatalogApiClient.cs
public async Task<List<Product>?> SearchProducts(string query, bool aiSearch)
{
if(aiSearch)
{
return await httpClient.GetFromJsonAsync<List<Product>>($”/products/aisearch/{query}”);
}
else
{
return await httpClient.GetFromJsonAsync<List<Product>>($”/products/search/{query}”);
}
}- If aiSearch == true, we call /products/aisearch/{query}, hitting the AI-based endpoint in the Catalog microservice.
Search.razor
@page “/search”
@attribute [StreamRendering(true)]
@rendermode InteractiveServer
@inject CatalogApiClient CatalogApiClient
<PageTitle>Search Products</PageTitle>
<p>Search our amazing outdoor products that you can purchase.</p>
<div class="form-group">
<label for="search" class="form-label">Type your question:</label>
<div class="input-group mb-3">
<input type="text" id="search" class="form-control" @bind="searchTerm" placeholder="Enter search term…" />
<button id="btnSearch" class="btn btn-primary" @onclick="DoSearch" type="submit">Search</button>
</div>
<div class="form-check form-switch mb-3">
<InputCheckbox id="aiSearchCheckBox" @bind-Value="aiSearch" />
<label class="form-check-label" for="aiSearch">Use Semantic Search</label>
</div>
<hr />
</div>
@if (products == null)
{
<p><em>Loading…</em></p>
}
else if (products.Count == 0)
{
<p><em>No product found.</em></p>
}
else
{
<table class="table">
<thead>
<tr>
<th>Image</th>
<th>Name</th>
<th>Description</th>
<th>Price</th>
</tr>
</thead>
<tbody>
@foreach (var product in products)
{
<tr>
<! - Simulating images being hosted on a CDN →
<td><img height="80" width="80" src="https://raw.githubusercontent.com/MicrosoftDocs/mslearn-dotnet-cloudnative/main/dotnet-docker/Products/wwwroot/images/@product.ImageUrl" /></td>
<td>@product.Name</td>
<td>@product.Description</td>
<td>@product.Price.ToString("C2")</td>
</tr>
}
</tbody>
</table>
}
@code {
private string searchTerm = default!;
private bool aiSearch = false;
private List<Product>? products = [];
private async Task DoSearch(MouseEventArgs e)
{
await Task.Delay(500);
products = await CatalogApiClient.SearchProducts(searchTerm, aiSearch);
}
}- <InputCheckbox @bind-Value=”aiSearch” /> toggles between standard or AI search.
- DoSearch calls CatalogApiClient.SearchProducts(searchTerm, aiSearch).
- The result is displayed in a table, or if none found, “No product found.” is shown.
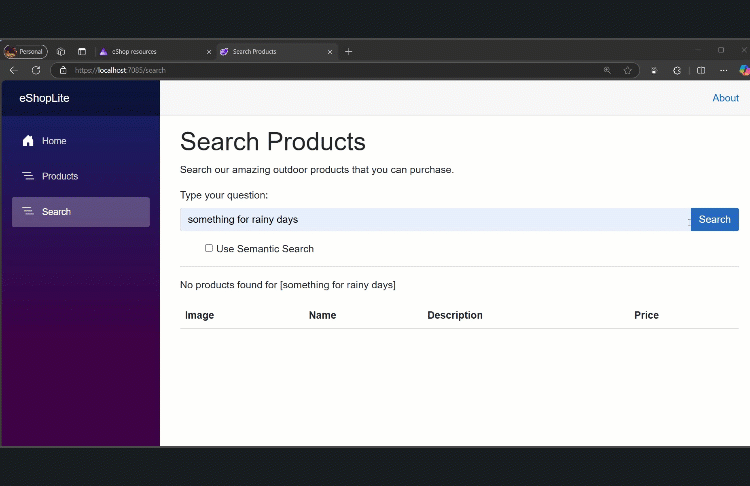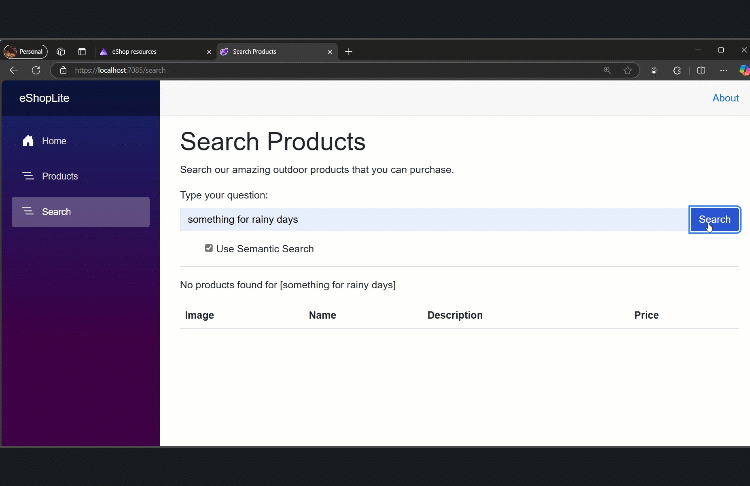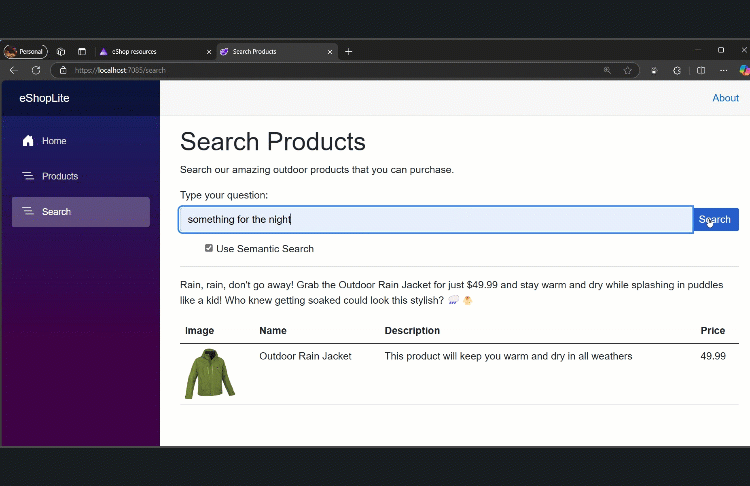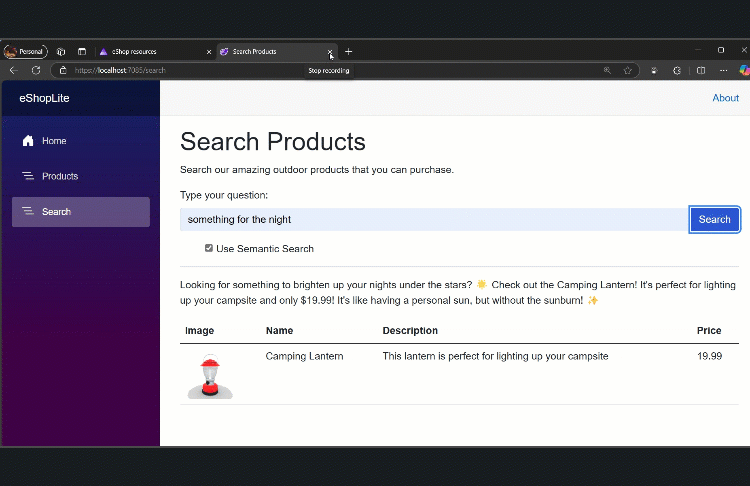
If aiSearch == false, the user runs a keyword search in the Catalog microservice’s ProductService. If aiSearch == true, we do an embedding search via ProductAISearchService. The Blazor UI updates dynamically to show the returned list of Product objects.
Conclusion
Building a semantic search pipeline in .NET is straightforward once you have a clear approach:
- Generate Embeddings with a local or cloud-based model (Ollama).
- Store & Query embeddings in a specialized VectorDB for quick similarity lookups.
- Integrate everything into your .NET application (ASP.NET Core, .NET Aspire, etc.) to serve semantic queries to your end users.
EShop-distributed GitHub Source Code: https://github.com/mehmetozkaya/eshop-distributed
Udemy Course: .NET Aspire and GenAI Develop Distributed Architectures — 2025
Develop AI-Powered Distributed Architectures using .NET Aspire and GenAI to develop EShop Catalog and Basket microservices integrate with Backing services including PostgreSQL, Redis, RabbitMQ, Keycloak, Ollama and Semantic Kernel to Create Intelligent E-Shop Solutions.
You will gain real-world experience, you will have a solid understanding of the .NET Aspire and .NET Generative AI to design, develop and deploy ai-powered distributed enterprise applications.
